Shell脚本
一、shell介绍
- 什么是shell
- shell功能
1.什么是shell
shell是一个程序,采用C语言编写,是用户和Linux内核沟通的桥梁。它既是一种命令语言,又是一种解释性的编程语言。通过一个图标来查看以下设立了的作用
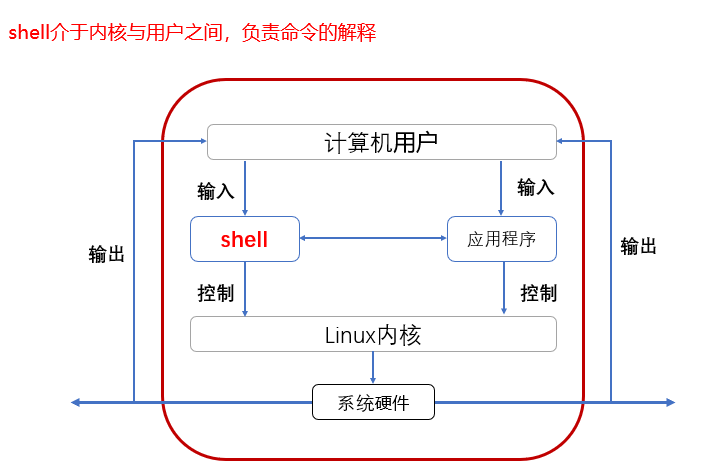
扩展知识
kernel(内核):为软件服务,接收用户或软件指令驱动硬件,完成工作;
shell:命令解释器
user:用户接口,对接用户
从上图可以看出,shell在操作系统中起到了承接用户和系统内核的作用。那为什么步直接用户对内核呢?
原因很简单,因为内核处理的都是二进制,而用户处理的都是高级语言。简而言之,如果没有shell,你希望告诉你喜欢的妹子:我爱你。你需要经过以下步骤:
- 将“我爱你”翻译成二进制
- 告诉内核
- 内核通过网卡发送给你的妹子
- 妹子计算机网卡收到你发的二进制
- 网卡交给内核
- 内核交给妹子
- 妹子看到都是一串01组成的数字,o my god,二进制不是人人都懂的,你的表白也就石沉大海了。
为了让所有人都能够快速、方便地使用计算机,我们打的系统开发人员通过shell解决了这个问题。使任何一个希望通过计算机来工作、娱乐的人都能够快速操作计算机。
2. shell功能
- 命令行解释功能
- 启动程序
- 输入输出重定向
- 管道连接
- 文件名置换(echo /*)
- 变量维护
- 环境控制
- shell编程
二、shell语法
- 如何书写一个shell脚本
- shell脚本运行
- shell中的特殊符号
- 管道
- 重定向
- shell中数学运算
- 脚本退出
**shell脚本就是将完成一个任务的所有命令按照执行的先后顺序,自上而下写入到一个文本文件中,然后给予执行权限。
1.如何书写一个shell脚本
shell脚本的命名:
名字要有意义,最好不要用a、b、c、d、1、2、3、4这中方式命名;虽然在linux系统中,文件没有扩展名的概念,依然建议你用.sh结尾;名字不要太长,最好能在30个字节以内解决。例如check_memory.sh
shell脚本格式:
shell脚本开头必须指定脚本运行环境,以#!这个特殊符号组合了组成。如: #!/bin/bash 指定该脚本是运行解析由/bin/bash来完成的:
shell中的注释使用#号
1 | shell脚本中,最好加入脚本说明字段 |
2.如何运行一个shell脚本
脚本运行需要执行权限,当我们给一个文件赋予执行权限后,该脚本就可以运行
1 | chmod u+x filename |
如果不希望赋予脚本执行权限,那么可以使用bash命令来运行未给予执行权限的脚本
1 | bash filename |
3. shell中的特殊符号
| 符号 | 描述 |
|---|---|
| ~ | 家目录 # cd ~ 代表进入用户家目录 |
| ! | 执行历史命令 ~~执行上一条命令 |
| $ | 变量中取内容符 |
| + - * / % | 对应数学运算 加 减 乘 除 取余 |
| & | 后台执行 |
| * | 型号是shell中的通配符,匹配所有 |
| ? | 问号是shell中的通配符,匹配除回车以外的一个字符 |
| ; | 分号可以在shell中一行执行多个命令,命令hi加用分号分隔 |
| | | 管道符,上一个命令的输出作为下一个命令的输入 cat filename | grep “abc” |
| \ | 转义字符 |
| `` | 反引号 命令中执行命令 echo “today is /date +%F/” |
| ‘ ‘ | 单引号,脚本中字符串要用单引号引起来,但不同于双引号的是,单引号不解释变量 |
| “ “ | 双引号,脚本中出现的字符串可以用双引号引起来 |
4. shell中管道的运用
| 管道符在shell中使用是最多的,很多组合命令都需要通过组合命令来完成输出。管道符其实就是下一个命令对上一个命令的输出做处理。
5. shell重定向
- > 重定向输入 覆盖原数据
- >> 重定向追加输入,在原数据的末尾添加
- < 重定向输出 wc -l < /etc/passwd
- << 重定向追加输出 fdisk /dev/sdb <
6. shell数学运算
expr 命令:只能做整数运算,格式比较古板,注意空格
1 | expr 1 + 1 |
使用bc计算器处理浮点运算,sacle=2代表小数点保留两位
1 | echo "scale=2;3+100"|bc |
双小圆括号运算,在shell中(())也可以用来做数学运算
1 | echo $(( 100+3)) |
7.退出脚本
exit NUM:退出脚本,释放系统资源,NUM代表一个整数,代表返回值。
三、shell格式化输出
- echo命令
- 颜色输出
一个程序需要有0个或以上输入,一个或更多输出
1. echo命令介绍
echo命令的功能是在显示器上显示一段文字,一般起到一个提示的作用。 该命令的一般格式为:echo [ -n ]字符串
其中选项n表示输出文字后不换行;字符串能加引号,也能不加引号。用echo命令输出加引号的字符串时,将字符串原样输出;用echo命令输出不加引号的字符串时,将字符串中的各个单词作为字符串输出,各字符串之间用一个空格分割。
功能说明:显示文字。
语法:
1 | echo [-ne][字符串] |
补充说明:echo会将输入的字符串送往标准输出。输出的字符串间以空白字符隔开,并在最后加上换行号。
命令选项:
-n:不要在最后自动换行;
-e:若字符串中出现以下字符,则特别加以处理,而不会将它当成一般文字输出:
转义字符:
| 转义字符 | 描述 |
|---|---|
| \a | 发出警告声 |
| \b | 删除前一个字符 |
| \c | 最后不加上换行符号 |
| \f | 换行但光标仍旧停留在原来的位置 |
| \n | 换行且光标移至行首 |
| \r | 光标移至行首,但不换行 |
| \t | 插入tab |
| \v | 与\f相同 |
| \\ | 插入\字符 |
| \nnn | 插入nnn(八进制)所代表的ASCII字符 |
举例:输出一个菜单
1 | !/bin/bash |
输出
1 | Fruit Shop |
2.颜色代码
脚本中echo显示内容带颜色显示,echo显示带颜色,需要使用参数-e
格式如下:
1 | echo -e “\033[字背景颜色;文字颜色m字符串\033[0m” |
例如:
1 | echo -e “\033[41;36m something here \033[0m” |
字背景颜色和文字颜色之间是英文的””
文字颜色后面有个m
字符串前后可以没有空格,如果有的话,输出也是同样有空格
1 | 下面是相应的字和背景颜色,可以自己来尝试找出不同颜色搭配 |
四、shell基本输入
- read命令
1. read命令
默认接受键盘的输入,回车符代表输入结束
| read 命令选项 | 描述 |
|---|---|
| -p | 打印信息 |
| -t | 限定时间 |
| -s | 不回显 |
| -n | 输入字符个数 |
五、shell变量
- 变量介绍
- 变量分类
- 变量管理
1.变量介绍
- 在编程中,我们总有一些数据需要临时存放在内存,以待后续使用时快速读出。内存在系统启动的时候被按照1B一个单位划分为若干个块,然后统一
- 编号(16进制编号),并对内存的使用情况做记录,保存在内存跟踪表中。
变量:变量是编程中最常用的一种临时在内存中存取数据的一种方式。
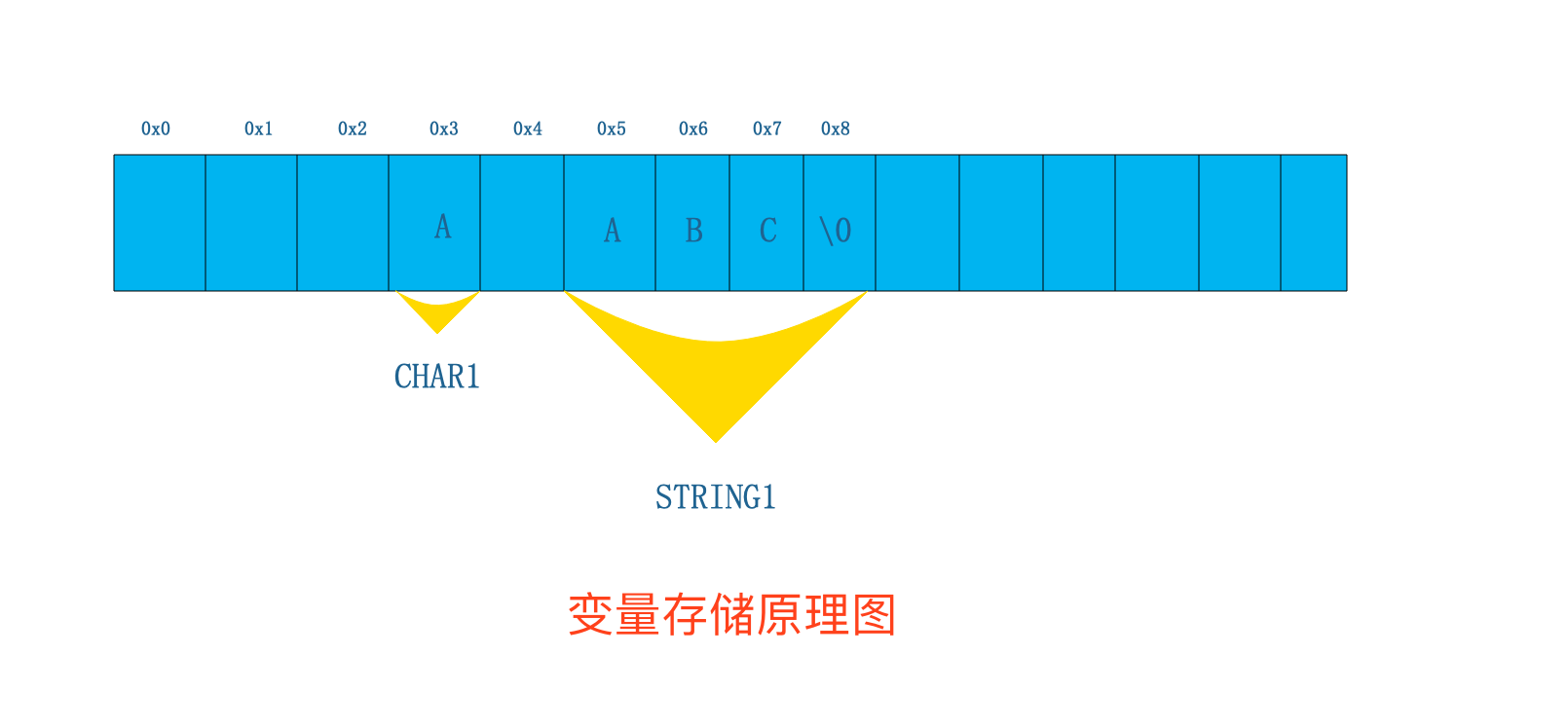
从图片可以看出,当我们在脚本中定义变量存值的时候,可以从以下方面看到变化:
内存占用:如果存的是一个字符则占用1个字节,如果存的是字符串则是字符串的长度加1个字节长度(\0是一个特殊字符,代表字符串结束)。
变量名与内存空间关系:计算机中会将对应的内存空间和变量名称绑定在一起,此时代表这段内存空间已经被程序占用,其他程序不可复用;然后将变量名对应的值存在对应内存地址的空间里。
2.变量分类
- 本地变量:用户私有变量,只有本用户可以使用,保存在家目录下的.bash_profile、.bashrc文件中
- 全局变量:所有用户都可以使用,保存在/etc/profile、/etc/bashrc文件中
- 用户自定义变量:用户自定义,比如脚本中的变量
3.定义变量
3.1定义变量
变量格式:变量名=值
在shell编程中的变量名和等号之间不能有空格
变量命名规则:
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)。
1 | VAR1=1 |
注意:字符串要用单引号或双引号引起来
3.2读取变量内容
读取变量内容符:$
读取方法:$变量名
1 | echo $name |
3.3取消变量unset
1 | unset name |
3.4定义全局变量export
1 | export name='Tom' |
注意:
上述设置的变量其实都是一次性变量,系统重启就会丢失。
如果希望本地变量或者全局变量可以永久使用,可以将需要设置的变量写入变量文件中即可。
3.5定义永久变量
本地变量:用户私有变量,只有本用户可以使用,保存在家目录下的.bash_profile、.bashrc文件中
全局变量:所有用户都可以使用,保存在/etc/profile、/etc/bashrc文件中
1 | 本地变量 |
六、shell数组
- 数组介绍
- 基本数组
- 关联数组
- 案列分享
1.数组介绍
一个变量只能存一个值,但是现实中又又很多值需要存储,那么变量就有些拘谨了。比如做一个学员信息表,一个班50个人,每个人6条信息,我们需要定义300个变量才能完成。恐怖恐怖,这只是一个班的学生,一个学校呢?一个市呢?……我想静静了!
仔细想想上述的案例,一个学生六个信息:ID、姓名、性别、年龄、成绩、班级。可不可以定义六个变量就能存储这六类信息呢?答案是当然可以的!变量不行,我们就用数组。
2.基本数组
数组可以让用户一次赋予多个值,需要读取数据时只需通过索引调用就可以方便读出了。
2.1数组语法
1 | 数组名称=(元素1 元素2 元素3 ...) |
2.2数组读出
1 | {数组名称[索引]} |
索引默认是元素在数组中的排队编号,默认第一个从0开始
2.3数组赋值
方法一:一次赋一个值
1 | array0[0]='tom' |
方法二: 一次赋多个值
1 | array2=(tom jack alice) |
2.4查看数组
1 | declare -a |
2.5访问数组元素
1 | echo ${array1[0]} #访问数组中的第一个元素 |
2.6遍历数组
默认数组通过数组元素的个数进行遍历
1 | echo ${ass_array2[index1]} |
方法二: 针对关联数组可以通过数组元素的索引进行遍历
3.关联数组
关联数组可以允许用户自定义数组的索引,这样使用起来更加方便、高效。
3.1定义关联数组
申明关联数组变量
1 | declare -A ass_array1 |
3.2关联数组赋值
方法一: 一次赋一个值
1 | 数组名[索引]=变量值 |
方法二: 一次赋多个值
1 | ass_array2=([index1]=tom [index2]=jack [index3]=alice [index4]=’bash shell’) |
3.3查看数组
1 | declare -A |
3.4访问数组元素
1 | echo ${ass_array2[index2]} #访问数组中的第二个元数 |
3.5遍历数组
通过数组元数的索引进行遍历,针对关联数组可以通过数组元素的索引进行遍历
1 | echo ${ass_array2[index1]} |
4.案例分享——学员信息系统
1 | !/bin/bash |
七、shell流程控制-if判断语句
- shell中的五大运算
- if语法
当我们在写程序的时候,时常对上一步执行是否成功如何判断苦恼,当我们今天学习了if就可以解决你的苦恼。if语句在我们程序中就是用来做判断的,以后大家不管学习什么语言,以后只要涉及到判断的部分,大家就可以直接拿if来使用,不同的语言之间的if只是语法不同,原理是相同的。
1. shell中的运算
1.1数学比较运算
运算符解释:
| 运算符 | 描述 |
|---|---|
| -eq | 等于 |
| -gt | 大于 |
| -lt | 小于 |
| -ge | 大于或等于 |
| -le | 小于或等于 |
| -ne | 不等于 |
1 | test 1 -eq 1;$? #0(shell中0为真,1为假) |
1.2字符串比较运算
运算符解释,注意字符串一定别忘了使用引号引起来
| 运算符 | 描述 |
|---|---|
| == | 等于 |
| != | 不等于 |
| -n | 检查字符串的长度是否大于0 |
| -z | 检查字符串的长度是否为0 |
1 | test 'abc' -n |
1.3文件比较与检查
| 运算符 | 描述 |
|---|---|
| -d | 检查文件是否存在且为目录 |
| -e | 检查文件是否存在 |
| -f | 检查文件是否存在且为文件 |
| -r | 检查文件是否存在且可读 |
| -s | 检查文件是否存在且不为空 |
| -w | 检查文件是否存在且可写 |
| -x | 检查文件是否存在且可执行 |
| -O | 检查文件是否存在并且被当前用户拥有 |
| -G | 检查文件是否存在并且默认组为当前用户组 |
1 | file1 -nt file2 检查file1是否比file2新 |
1 | test -d /opt/shell;echo $? #0 |
1.4逻辑运算
| 运算符 | 描述 |
|---|---|
| && | 逻辑与运算 |
| || | 逻辑或运算 |
| ! | 逻辑非运算 |
1 | if [ 1 -eq 1 ] && [ 2 -eq 2 ];then echo "yes";else echo "no";fi #yes |
逻辑运算注意事项:逻辑与 或 运算都需要两个或以上条件,逻辑非运算只能一个条件。
1.5赋值运算
=:赋值运算符
1 | a=10 |
2. if语法
2.1语法一:单if语句
适用范围:只需要一步判断,条件返回真干什么或者条件返回假干什么。
语句格式
1 | if [ condition ] #condition 值为true or false |
判断当前用户是不是root,如果不是那么返回”ERROR: need to be root so that!“
1 | !/bin/bash |
2.2语法二:if-then-else语句
适用范围:两步判断,条件为真干什么,条件为假干什么。
1 | if [ condition ] |
判断当前登录用户是管理员还是普通用户,如果是管理员输出”hey admin“ 如果是普通用户输出”hey guest“
1 | if [ $USER == 'root' ] |
2.3语法三:if-then-elif语句
适用范围:多于两个以上的判断结果,也就是多于一个以上的判断条件。
1 | if [ condition 1] |
通过一个脚本,判断两个整数的关系。
1 | if [ $1 -gt $2 ] |
3. if高级应用
- 条件符号使用双圆括号,可以在条件中植入数学表达式
1 | if (( 100%3+1>1 ));then |
注意 双小圆括号中的比较运算符 使用的是我们传统的比较运算符 >>= == <<= !=
- 使用双方括号,可以在条件中使用通配符
为字符串提供高级功能,模式匹配 r* 匹配r开头的字符串
1 | !/bin/bash |
为字符串提供高级功能,模式匹配 r* 匹配r开头的字符串
八、shell流程控制-for循环语句
- for循环介绍
- for语法
- 循环控制
脚本在执行任务的时候,总会遇到需要循环执行的时候,比如说我们需要脚本每隔五分钟执行一次ping的操作,除了计划任务,我们还可以使用脚本来完成,那么我们就用到了循环语句。
1. for 循环介绍
很多人把for循环叫做条件循环,或者for i in 。其实前者说的就是for的特性,for循环的次数和给予的条件是成正比的,也就是你给5个条件,那么他就循环5次;后者说的是for的语法。
循环的优点:
- 节省内存(完成同一个任务)
- 结构更清晰
- 节省时间成本
2. for语法
2.1 for 语法一
1 | for var in value1 value2 ...... |
循环输出1-9数字
1 | !/bin/bash |
2.2 for语法二
C式的for命令
1 | for ((变量;条件;自增减运算 )) |
输出1-9
1 | !/bin/bash |
for循环使用多个变量
1 | !/bin/bash |
for 无限循环 使用((;;)) 条件可以实现无线循环
1 | !/bin/bash |
3.循环控制语句
3.1 sleep N 脚本执行到该步休眠N秒
1 | !/bin/bash |
3.2 continue 跳过循环中的某次循环
默认循环输出1-9,但是使用continue跳过输出5
1 | !/bin/bash |
3.3 break 跳出循环继续执行后续代码
默认循环输出1-9,当输出到5的时候跳出循环
1 | !/bin/bash |
3.4实例
1 | 监控主机存活的脚本 |
九、shell流程控制-while循环语句
- while循环介绍
- while循环语法
- while实战
1. while循环介绍
while在shell中也是负责循环的语句,和for一样。因为功能一样,很多人在学习和工作中的脚本遇到循环到底该使用for还是while呢?很多人不知道,就造就了有人一遇到循环就是for或者一位的while。我个人认为可以按照我说的这个思想来使用,既知道循环次数就可以用for,比如说一天需要循环24次;如果不知道代码要循环多少次,那就用while,比如我们作业中要求写的猜数字,每个人猜对一个数字的次数都是不能固定的,也是未知的。所以这样的循环我就建议大家用while了。
2.while循环语法
1 | while [ condition ] #注意,条件为真while才会循环,条件为假,while停止循环 |
丈母娘选女婿条件:
1 | read -p "money:" money |
3. while实战
- 使用while 遍历文件内容
1 | 使用while遍历文件内容 |
- 使用while读出文件中的列,IFS指定默认的列分隔符
1 | 使用while读出文件中的列,IFS指定默认的列分隔符 |
- 九九乘法表
1 | 九九乘法表 |
十、shell流程控制-until循环语句
- until介绍
- until语法
- 案例分享
1. until介绍
和while正好相反,until是条件为假开始执行,条件为真停止执行。
2. until语法
1 | until [ condition ] #注意,条件为假until才会循环,条件为真,until停止循环 |
3.案例
- 打印10-20数字
1 | !/bin/bash |
十一、shell流程控制-case条件判断语句
- case介绍
- case语法
- shell特殊变量
1. case介绍
在生产环境中,我们总会遇到一个问题需要根据不同的状况来执行不同的预案,那么我们要处理这样的问题就要首先根据可能出现的情况写出对应预案,根据出现的情况来加载不同的预案。
特点:根据给予的不同条件执行不同的代码块
2. case语法
1 | case 变量 in |
注意:每个代码块执行完毕要以;;结尾代表结束,case结尾要以倒过来写的esac来结束。
案例说明
1 | !/bin/bash |
3. shell特殊变量
特殊参数:
| 参数 | 作用 |
|---|---|
| $* | 代表所有参数,其间隔为IFS内定参数的第一个字元 |
| $@ | 与*星号类同。不同之处在於不参照IFS |
| $# | 代表参数数量 |
| $ | 执行上一个指令的返回值 |
| $- | 最近执行的foreground pipeline的选项参数 |
| $N | shell的第几个外传参数 |
| $_ | 显示出最後一个执行的命令 |
| $$ | 本身的Process ID |
| $0 | 脚本的名字 |
十二、shell函数
- 函数介绍
- 函数语法
- 函数应用
- 实战
1.函数介绍
在写代码的时候,我们很多人习惯从头写到结束,完成以后在一起测试。但是到测试阶段才发现:错误一大堆,上帝啊!弄死我吧!
为了解决这个问题,建议大家把代码模块化,一个模块实现一个功能,哪怕是一个很小的功能都可以,这样的话我们写代码就会逻辑上比较简单,代码量比较少,排错简单,这也就是函数的好处。
函数的优点:
- 代码模块化,调用方便,节省内存
- 代码模块化,代码量少,排错简单
- 代码模块化,可以改变代码的执行顺序
2.函数的语法
语法一:
1 | 函数名 () { |
语法二:
1 | function 函数名 { |
3.函数的应用
3.1定义一个函数
1 | print () { |
或者
1 | function hello { |
print 和 hello就是函数的名字,函数名字命名参考变量一节中的变量命名规则
3.2函数应用
定义好函数后,如果想调用该函数,只需通过函数名调用即可。
1 | !/bin/bash |
4.实战
nginx启动管理脚本
1 | !/bin/bash |
十三、正则表达式
- 正则表达式介绍
- 特殊字符
- POSIX特殊字符
1.正则表达式介绍
正则表达式是一种文本模式匹配,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为”元字符”)。它是一种字符串匹配的模式,可以用来检查一个字符串是否含有某种子串、将匹配的子串替换或者从某个字符串中取出某个条件的子串。
正则表达式就像数学公式一样,我们可以通过正则表达式提供的一些特殊字符来生成一个匹配对应字符串的公式,用此来从海量数据中匹配出自己想要的数据。
正则表达式是一个三方产品,被常用计算机语言广泛使用,比如:shell、PHP、python、java、js等!
shell也支持正则表达式,但不是所有的命令都支持正则表达式,常见的的命令中只有grep、sed、awk命令支持正则表达式。
2.特殊字符
定位符使用技巧:同时锚定开头和结尾,做精确匹配;单一锚定开头和结尾,做模糊匹配。
| 定位符 | 说明 |
|---|---|
| ^ | 锚定开头 ^a 以a开头 默认锚定一个字符 |
| $ | 锚定结尾 a$ 以a结尾 默认锚定一个字符 |
1 | 精确匹配 以a开头c结尾的字符串 |
匹配符:匹配字符串
| 匹配符 | 说明 |
|---|---|
| . | 匹配除回车以外的任意字符 |
| ( ) | 字符串分组 |
| [ ] | 定义字符类,匹配括号中的一个字符 |
| [ ^ ] | 表示否定括号中出现字符类中的字符,取反 |
| \ | 转义字符 |
| | | 或 |
1 | 精确匹配 以a开头c结尾 中间任意 长度为三个字节的字符串 |
限定符:对前面的字符或者字符串做限定说明
| 限定符 | 说明 |
|---|---|
| * | 某个字符之后加星号表示该字符不出现或出现多次 |
| ? | 与星号相似,但略有变化,表示该字符出现一次或不出现 |
| + | 与星号相似,表示其前面字符出现一次或多次,但必须出现一次 |
| {n,m} | 某个字符之后出现,表示该字符最少n次,最多m次 |
| {m} | 正好出现了m次 |
1 | 精确匹配 以a开头 c结尾 中间是有b或者没有b 长度不限的字符串 |
3. POSIX特殊字符
| 特殊字符 | 说明 |
|---|---|
| [:alnum:] | 匹配任意字母字符0-9 a-z A-Z |
| [:alpha:] | 匹配任意字母,大写或小写 |
| [:digit:] | 数字 0-9 |
| [:graph:] | 非空字符( 非空格控制字符) |
| [:lower:] | 小写字符a-z |
| [:upper:] | 大写字符A-Z |
| [:cntrl:] | 控制字符 |
| [:print:] | 非空字符( 包括空格) |
| [:punct:] | 标点符号 |
| [:blank:] | 空格和TAB字符 |
| [:xdigit:] | 16 进制数字 |
| [:space:] | 所有空白字符( 新行、空格、制表符) |
注意 [[ ]] 双中括号的意思: 第一个中括号是匹配符[]匹配中括号中的任意一个字符,第二个[]是格式 如[:digit:]
1 | 精确匹配 以a开头c结尾 中间a-zA-Z0-9任意字符 长度为三个字节的字符串 |
案例
- 匹配合法的IP地址
1 | egrep '^((25[0-5]|2[0-4][[:digit:]]|[01]?[[:digit:]][[:digit:]]?).){3}(25[0-5]|2[0-4][[:digit:]]|[01]?[[:digit:]][[:digit:]]?)$' —color ip.txt |
- 匹配座机电话号码
1 | egrep '^[[:graph:]]{12}$” number |egrep “^(0[1-9][0-9][0-9]?)-[1-9][0-9]{6,7}$' |
十四、shell对文件的操作
- 简介
- sed命令
- sed小技巧
- 实战
1.简介
在shell脚本编写中,时常会用到对文件的相关操作,比如增加内容,修改内容,删除部分内容,查看部分内容等,但是上述举例的这些操作一般都是需要在文本编辑器中才能操作,常用的文本编辑器如:gedit、vim、nano等又是交互式文本编辑器,脚本无法自己独立完成,必须有人参与才可以完成。如果这样的话又违背了我们编写脚本的意愿(全部由机器来完成,减少人的工作压力,提升工作效率)。emm….如何才能让这些操作全部脚本自己就搞定,而不需要人的参与,而且又能按照我们的脚本预案来完成呢?
为了解决上述问题,linux为大家提供了一些命令,比如Perl、sed等命令,今天我就着重为大家介绍一下sed命令。
2.sed命令
sed是linux中提供的一个外部命令,它是一个行(流)编辑器,非交互式的对文件内容进行增删改查的操作,使用者只能在命令行输入编辑命令、指定文件名,然后在屏幕上查看输出。它和文本编辑器有本质的区别。
区别:
文本编辑器: 编辑对象是文件
行编辑器:编辑对象是文件中的行
也就是前者一次处理一个文本,而后者是一次处理一个文本中的一行。这个是我们应该弄清楚且必须牢记的,否者可能无法理解sed的运行原理和使用精髓。
2.1 sed数据处理原理
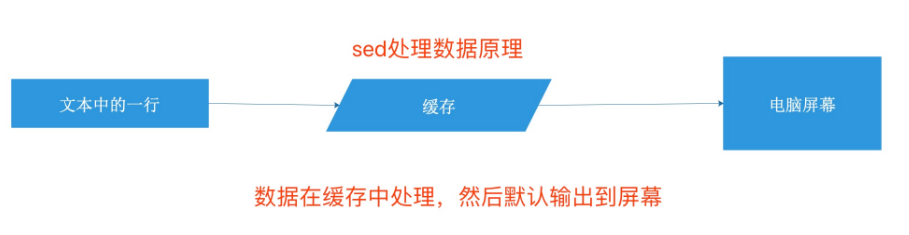
2.2 sed命令
语法:
1 | sed [options] '{command}[flags]' [filename] |
命令选项[options]
| 选项[options] | 定义 |
|---|---|
| -e script | 将脚本中指定的命令添加到处理输入时执行的命令中 多条件,一行中要有多个操作 |
| -f script | 将文件中指定的命令添加到处理输入时执行的命令中 |
| -n | 抑制自动输出 |
| -i | 编辑文件内容 |
| -i.bak | 修改时同时创建.bak备份文件 |
| -r | 使用扩展的正则表达式 |
| ! | 取反 (跟在模式条件后与shell有所区别) |
常用内部命令{command}
| 命令{command} | 定义 |
|---|---|
| a | 在匹配后面添加 |
| i | 在匹配前面添加 |
| p | 打印 |
| d | 删除 |
| s | 查找替换 |
| c | 更改 |
| y | 转换 N D P |
标志位[flags]
| 标志[flags] | 定义 |
|---|---|
| 数字 | 表示新文本替换的模式 |
| g | 表示用新文本替换现有文本的全部实例 |
| p | 表示打印原始的内容 |
| w filename | 将替换的结果写入文件 |
2.2.1 sed内部命令说明
- 文件内容增加操作,将数据追加到某个位置之后,使用命令a。
1 | 在data1的每行后追加一行新数据内容: append data "haha" |
//开启匹配模式 /要匹配的字符串/
- 文件内容增加操作,将数据插入到某个位置之前,使用命令i。
1 | 在data1的每行前插入一行新数据内容: insert data "haha" |
- 文件内容修改操作—替换,将一行中匹配的内容替换为新的数据,使用命令s。
1 | 从标准输出流中做替换,将test替换为text |
- 文件内容修改操作—更改,将一行中匹配的内容替换为新的数据,使用命令c。
1 | 将data1文件中的所有行的内容更改为: change data "data" |
- 文件内容修改操作—字符转换,将一行中匹配的内容替换为新的数据,使用命令y。
1 | 将data1中的a b c字符转换为对应的 A B C字符 |
- 文件内容删除,将文件中的指定数据删除,使用命令d。
1 | 删除文件data1中的所有数据 |
- 文件内容查看,将文件内容输出到屏幕,使用命令p。
1 | 打印data1文件内容 |
可以看得出,打印内容是重复的行,原因是打印了指定文件内容一次,又将读入缓存的所有数据打印了一次,所以会看到这样的效果,如果不想看到这样的结果,可以加命令选项-n抑制内存输出即可
2.2.2命令选项说明
- 在命令行中使用多个命令 -e
1 | 将brown替换为green dog替换为cat |
- 从文件读取编辑器命令 -f 适用于日常重复执行的场景
1 | 1)将命令写入文件 |
- 抑制内存输出 -n
1 | 打印data1文件的第二行到最后一行内容 $最后的意思 |
- 使用正则表达式 -r
1 | 打印data1中以字符串"3 the"开头的行内容 |
- 从上述的演示中,大家可以看出,数据处理只是在缓存中完成的,并没有实际修改文件内容,如果需要修改文件内容可以直接使用-i命令选项。在这里我需要说明的是-i是一个不可逆的操作,一旦修改,如果想复原就很困难,几乎不可能,所以建议大家在操作的时候可以备份一下源文件。-i命令选项提供了备份功能,比如参数使用-i.bak,那么在修改源文件的同时会先备份一个以.bak结尾的源文件,然后再进行修改操作。
1 | 执行替换命令并修改文件 |
2.2.3标志
- 数字标志:此标志是一个非零正数,默认情况下,执行替换的时候,如果一行中有多个符合的字符串,如果没有标志位定义,那么只会替换第一个字符串,其他的就被忽略掉了,为了能精确替换,可以使用数字位做定义。
1 | 替换一行中的第二处dog为cat |
- g标志:将一行中的所有符合的字符串全部执行替换
1 | 将data1文件中的所有dog替换为cat |
- p标志:打印文本内容,类似于-p命令选项
1 | 将data2文件第三行中的dog换成cat并打印 |
- w filename标志:将修改的内容存入filename文件中
1 | 将data2文件第三行中的dog换成cat并保存在text文件中 |
3. sed小技巧
$= 统计文本有多少行
1 | 统计data2有多少行 |
4.实战
DNS监测WEB服务状态,并根据其状态实现高可用解析
场景:通过DNS进行单域名多条A记录解析做负载均衡。
1 | !/bin/bash |
十五、shell对输出流的处理
- awk介绍
- awk基本用法
- awk高级用法
- awk小技巧
在日常计算机管理中,总会有很多数据输出到屏幕或者文件,这些输出包含了标准输出、标准错误输出。默认情况下,这些信息全部输出到默认输出设备—-屏幕。然而,大量的数据输出中,只有一小部分是我们需要重点关注的,我们需要把我们需要的或者关注的这些信息过滤或者提取以备后续需要时调用。早先的学习中,我们学过使用grep来过滤这些数据,使用cut、tr命令提出某些字段,但是他们都不具备提取并处理数据的能力,都必须先过滤,再提取转存到变量,然后在通过变量提取去处理,比如:
内存使用率的统计步骤:
- 通过free -m提取出内存总量,赋值给变量 memory_totle
- 通过free -m提取出n内存使用量,赋值给变量memory_use
- 通过数学运算计算内存使用率
需要执行多步才能得到内存使用率,那么有没有一个命令能够集过滤、提取、运算为一体呢?当然,就是今天我要给大家介绍的命令:awk
平行命令还有gawk、pgawk、dgawk
1. awk介绍
awk是一种可以处理数据、产生格式化报表的语言,功能十分强大。awk 认为文件中的每一行是一条记录 记录与记录的分隔符为换行符,每一列是一个字段 字段与字段的分隔符默认是一个或多个空格或tab制表符.
awk的工作方式是读取数据,将每一行数据视为一条记录(record)每条记录以字段分隔符分成若干字段,然后输出各个字段的值.
awk语法:
1 | awk [options] [BEGIN]{program} [END][file] |
常用命令选项
| 选项 | 描述 |
|---|---|
| -F fs | 指定描绘一行中数据字段的文件分隔符 默认为空格 |
| -f file | 指定读取程序的文件名 |
| -v var=value | 定义awk程序中使用的变量和默认值 |
注意:awk 程序脚本由左大括号和右大括号定义。脚本命令必须放置在两个大括号之间。由于awk命令行假定脚本是单文本字符串,所以必须将脚本包括在单引号内。
awk程序运行优先级是:
- BEGIN: 在开始处理数据流之前执行,可选项
- program: 如何处理数据流,必选项
- END: 处理完数据流后执行,可选项
2. awk的基本用法—-awk数据提取功能
2.1 awk对字段(列)的提取
字段提取:提取一个文本中的一列数据并打印输出
字段相关内置变量
| 变量 | 描述 |
|---|---|
| $0 | 表示整行文本 |
| $1 | 表示文本行中的第一个数据字段 |
| $2 | 表示文本行中的第二个数据字段 |
| $N | 表示文本行中的第N个数据字段 |
| $NF | 表示文本行中的最后一个数据字段 |
1 | 读入test每行数据并把每行数据打印出来 |
2.2命令选项详解
-F: 指定字段与字段的分隔符
当输出的数据流字段格式不是awk默认的字段格式时,我们可以使用-F命令选项来重新定义数据流字段分隔符。比如:处理的文件是/etc/passwd,希望打印第一列、第三列、最后一列
1 | awk -F ':' '{print $1,$3,$NF}' /etc/passwd |
可以看的出,awk输出字段默认的分隔符也是空格
-f file: 如果awk命令是日常重复工作,而又没有太多变化,可以将程序写入文件,每次使用-f调用程序文件就好,方便,高效。
1 | awk -f abc test #abc是文件名 |
-v 定义变量,既然作者写awk的时候就是按着语言去写的,那么语言中最重要的要素—-变量肯定不能缺席,所以可以使用-v命令选项定义变量
1 | 定义一个变量 name=baism,然后调用变量读出数据 |
2.3 awk对记录(行)的提取
记录提取:提取一个文本中的一行并打印输出
记录的提取方法有两种:a、通过行号 b、通过正则匹配
记录相关内置变量
NR: 指定行号
1 | 提取test第三行数据 |
2.4 awk对字符串提取
记录和字段的汇合点就是字符串
1 | 打印test第三行的第六个字段 |
2.5 awk程序的优先级
关于awk程序的执行优先级,BEGIN是优先级最高的代码块,是在执行PROGRAM之前执行的,不需要提供数据源,因为不涉及到任何数据的处理,也不依赖与PROGRAM代码块;PROGRAM是对数据流干什么,是必选代码块,也是默认代码块。所以在执行时必须提供数据源;END是处理完数据流后的操作,如果需要执行END代码块,就必须需要PROGRAM的支持,单个无法执行。
1 | awk 'BEGIN{print "hello ayitula"}{print $0}END{print "bye ayitula"}' test |
3. awk高级用法
awk是一门语言,那么就会符合语言的特性,除了可以定义变量外,还可以定义数组,还可以进行运算,流程控制,我们接下来看看吧。
3.1 awk定义数组
数组定义方式: 数组名[索引]=值
1 | 定义数组array,有两个元素,分别是100,200,打印数组元素 |
3.2 awk运算
| 运算类型 | 运算符 |
|---|---|
| 赋值运算 | = |
| 比较运算 | > >= == < <= != |
| 数学运算 | + - * / % ** ++ — |
| 逻辑运算 | && || |
| 匹配运算 | ~ !~ |
- 赋值运算:主要是对变量或者数组赋值
1 | awk -v name='baism' 'BEGIN{print name}' |
- 比较运算,如果比较的是字符串则按ascii编码顺序表比较。如果结果返回为真则用1表示,如果返回为假则用0表示
1 | awk 'BEGIN{print "a" >= "b" }' #0 |
- 数学运算
1 | awk 'BEGIN{print 100+3 }' #103 |
- 逻辑运算
1 | awk 'BEGIN{print 100>=2 && 100>=3 }' #1 |
- 匹配运算
1 | 匹配/etc/passwd文件中,第一个字段是ro开头的那一行 |
3.3 awk 环境变量
| 变量 | 描述 |
|---|---|
| FIELDWIDTHS | 以空格分隔的数字列表,用空格定义每个数据字段的精确宽度 |
| FS | 输入字段分隔符号 |
| OFS | 输出字段分隔符号 |
| RS | 输入记录分隔符 |
| ORS | 输出记录分隔符号 |
- FIELDWIDTHS:重定义列宽并打印,注意不可以使用$0打印所有,因为$0是打印本行全内容,不会打印你定义的字段
1 | 输出/etc/passwd文件第一行中的第1,2,3列,并且第一列是5个字符,第二列2个字符,第三列8个字符 |
- FS:指定数据源中字段分隔符,类似命令选项-F
1 | 指定数据源字段的分隔符为':' |
- OFS:指定输出到屏幕后字段的分隔符
1 | 指定数据源字段的分隔符为':',并指定输出字段的分隔符为'-' |
- RS:指定输入记录(行)的分隔符,默认是回车
1 | 把输入所有记录(行)的分隔符都设置为空 |
将记录的分隔符修改为空行后,所有的行会变成一行,所以所有字段就在一行了。
- ORS:输出到屏幕后记录(行)的分隔符,默认为回车
1 | 把输入所有记录(行)的分隔符都设置为空,输出记录(行)的分隔符设置为* |
3.4流程控制
- if判断语句
- for循环语句
- while循环语句
- do…while语句
- 循环控制
if判断语句
1 | 打印$1大于5的行 |
for循环语句
1 | 将一行中的数据都加起来 $1+$2+$3 |
while循环语句
1 | 将文件中的每行的数值累加,和大于或等于150就停止累加 |
do…while循环语句
1 | awk '{sum=0;i=1;do{sum+=$i;i++}while(sum<150);print sum}' num2 |
循环控制语句
1 | 累加每行数值,和大于150停止累加 |
4. awk小技巧
1 | 打印test文本的行数 |
5.实战
练习一
1 | [root@www ~]# cat contacts |
练习二
1 | [root@www ~]# cat ip |
练习三
1 | [root@www ~]# cat num |
练习四
1 | 统计当前所有连接状态的数量 |
练习五
1 | 用awk命令 获取100以内能被7整除,而且包含7的数字 |
- Post title:Shell脚本
- Post author:John_Frod
- Create time:2021-01-29 22:01:18
- Post link:https://keep.xpoet.cn/2021/01/29/Shell脚本/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.